Mit der zunehmenden Automatisierung der industriellen Prozesse und der steigenden Produktivität in diesem Sektor fallen täglich Giga- bis Petabytes an Daten aus Sensoren, Kameras oder Enterprise Systemen an. Eine wesentliche Herausforderung ist die Heterogenität der Daten bzgl. Umfang, Struktur und Geschwindigkeit, wobei jede Datenquelle stets eine eingeschränkte, teils einfältige Sicht auf die Realität darstellt. Heutige ML-Verfahren werden in der Regel nur auf eine oder wenige Sichten angewandt. Bewährte ML-Methoden (z.B. Gradient Boosting) sind schnell und recht flexibel nutzbar, aber bedingen viel Aufwand im Feature-Engineering. Deep-Learning-Verfahren (DL) haben hier einen großen Vorteil, sind aber oftmals auf reale Daten nicht anwendbar, z.B. wenn zu wenige Trainingsbeispiele existieren oder wenn eine Erklärbarkeit der Ergebnisse nötig ist. Hier können strukturierte Machine-Learning-Verfahren (SML) auf Wissensgraphen punkten. Diese sind aber nur schwer auf unstrukturierte Daten, wie Bilder oder akustische Sensoren, anwendbar. Diese Abwägung hat in heutigen KI-Projekten zur Folge, dass man sich in der Regel für eine reduzierte Datensicht, sich damit auf bestimmte Verfahren festlegt und häufig nicht das volle Potential bestehender KI-Verfahren ausnutzen kann.
Ziele
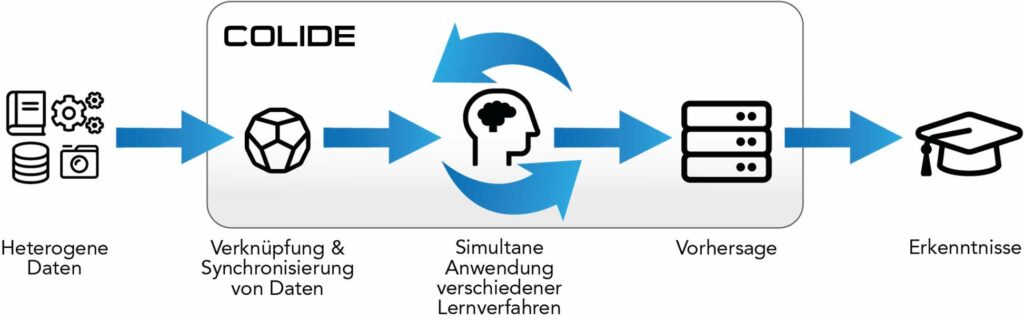
Das Ziel von COLIDE ist die Entwicklung von Auto-Multi-View-Learning Verfahren (AutoMVL) für heterogene Industriedaten. Dazu werden multi-view learning (MVL) und automatisiertes maschinelles Lernen (AutoML) erstmals kombiniert. Damit werden insbesondere KMUs in die Lage versetzt, den Mehrwert der simultanen Nutzung verschiedenster ML-Methoden auf heterogenen Datenquellen kosteneffizient zu erfahren und so innovative, datengetriebene Lösungen insbesondere in der Produktion anzubieten. Die Machbarkeit wird anhand von 2 realen, diskjunkten Anwendungsfällen aufgezeigt.
Das Ergebnis von COLIDE ermöglicht auch nicht-KI-Experten eine agilere und effektivere Anwendung verschiedener ML-Verfahren und kann dadurch dedizierte Informationen für Optimierung und Effizienzsteigerung seiner Anwendungsumgebung erhalten. Beim Kunden werden langwierige, kostenintensive Analyse- und KI-Auswahlverfahren reduziert und an seine spezifischen Anforderungen angepasst. Dem Nutzer werden die verwendeten ML-Verfahren für seine Anwendungsumgebung angezeigt und ihm die Auswahl und Vorteile der jeweiligen Verfahren verständlich erläutert. Das Ziel ist es ein generell besseres Verständnis für KI-Verfahren zu vermitteln und einen Wissenstransfer zu ermöglichen. Hierzu gehört auch, dass die genutzten SML-Verfahren von Grund auf erklärbar sind. Letztlich werden sich Produktkosten aufgrund der Vermeidung langwieriger Prüf- und Auswertungsverfahren senken, was Endverbraucher entgegenkommt.

Dieses Projekt wird durch das Bundesministerium für Bildung und Forschung (BMBF) finanziert mit dem Förderkennzeichen: 01IS21005 und dem Förderbereich: KI4KMU.